Iniciação à Pesquisa Científica em Saúde /REPOSITÓRIO DE EXERCÍCIOS RESOLVIDOS/ Exercício 41: Saúde materno-infantil I
Questão 41 - Saúde materno-infantil I
editar
Um estudo observacional descritivo foi realizado em uma maternidade de referência com o objetivo de avaliar os indicadores de qualidade da assistência materno-infantil. Para isto, uma amostra aleatória foi extraída a partir de uma base de dados clínicos que registra sistematicamente os dados sobre o parto, no momento da alta hospitalar.
Utilize a Base de Dados: BD_PARTOS.sav e o software estatístico SPSS existente nos laboratórios de informática da UFMG, ou outro de livre acesso que você quiser (EPI-INFO).
a) O peso médio ao nascer é diferente entre os sexos? (variável PED_PESO, em gramas e variável SEXO_RN, onde 1=masculino e 2=feminino)
b) A ocorrência de asfixia neonatal está associada a presença de risco gestacional? (variável BAIXO_APGAR5 e variável ALTO_RISCO)
Formule hipóteses nula para a população de mulheres gestantes e recém-nascidos, cuja probabilidade podemos inferir a partir desta amostra. Escolha um teste estatístico e execute-o, interpretando as saída. Para responder as questões da pesquisa, coloque as saídas computacionais, justificando suas respostas.
Sugestão de apoio:
Resposta da questão:
editarA)
A partir das informações do enunciado e do banco de dados disponibilizado, formula-se a seguinte hipótese nula:
O peso médio dos indivíduos do sexo masculino (μm) ao nascer é igual ao peso médio dos indivíduos do sexo feminino (μf). Logo, em representação:
Ho: μm = μf
Assim, a hipótese alternativa também é elaborada:
Ha : μm ≠ μf (o peso médio dos indivíduos do sexo masculino ao nascer é diferente ao peso médio dos de sexo feminino).
O teste escolhido será o “Teste T de Student para amostras independentes” na medida que se tratam de variáveis categóricas (sexo feminino e sexo masculino) relacionadas a variáveis numéricas (peso ao nascimento); são amostras e observações independentes (pessoas do sexo feminino e pessoas do sexo masculino); e cada participante é contabilizado uma única vez. Além disto, para se utilizar o teste-t de médias para amostras independentes é preciso que as variáveis sejam numéricas e que apresentem distribuição normal (ou que tende para normal) nos subgrupos analisados (sexo masculino e sexo feminino).
Em seguida, determina-se o nível de significância (α). Devido ao tamanho da amostra utilizada e ao melhor intervalo de confiança desejado, escolhe-se o α=5% .
Determinando-se os parâmetros acima e utilizando o software “SPSS”, prossegue-se com o cálculo da estatística do teste.
Obs.: Abre-se a base de dados no aplicativo SPSS. Clique em “Analyze” >> “Compare Means”>> “Independent-Samples T test”. No campo “Grouping Variable”, preencha com a informação “SEXO_RN”. No campo “Test Variable”, adicione a informação “PED_PESO”. Clique em “Define Groups” e preencha os campos com “1” e “2” respectivamente (esses dados referem-se aos sexos). Clique em OK e verifique a tabela gerada:

RESPOSTA : O p-value encontrado no Teste de T de Student de amostras independentes resultou em valor superior (6,3%) ao nível de significância, isto é, 5%. Como esse não ultrapassou a região crítica para a significância estatística, ACEITA-SE A HIPÓTESE NULA. Assim, o peso médio ao nascer é igual em ambos os sexos.
---------------------------------------------------SÍNTESE DO CONTEÚDO ABORDADO ANTERIORMENTE--------------------
A partir dos dados amostrais, pretendemos realizar inferências acerca dos parâmetros desconhecidos da população. Estas inferências são feitas em dois sentidos, estimando os respectivos parâmetros ou testando hipóteses em relação aos seus valores. Essa estatistica inferencial pode ser realizada por meio do teste de hipóteses. Um teste de hipóteses é um processo estatístico usado para se tirar uma conclusão do tipo “sim ou não” sobre uma ou mais populações, a partir de uma ou mais amostras dessas populações. É sabido também que uma hipótese estatística é uma alegação, ou afirmação, sobre uma propriedade de uma população.
A hipótese nula (denotada por Ho) é uma afirmação sobre o valor de um parâmetro populacional, deve conter a condição de igualdade e ser descrita por igualdade de valores (médias, como na questão abordada) ou inequações (> e igual ou < e igual) entre valores. A hipótese alternativa (denotada por Ha) é uma afirmação que deve ser verdadeira se a hipótese nula é falsa.
O p-value é o menor nível de significância (α) a partir do qual se começa a rejeitar a hipótese nula Ho, ou seja, se α > p-value então deve-se rejeitar H0.
Para você decidir se uma hipótese é verdadeira ou falsa, ou seja, se ela deve ser aceita ou rejeitada, considerando uma determinada amostra, precisamos seguir uma série de passos. Os passos são mostrados a seguir.
1) Definir a hipótese de igualdade (Ho) e a hipótese alternativa (Ha) para tentar rejeitar Ho
2) Definir o nível de significância (α).
3) Definir a distribuição amostral a ser utilizada.
4) Definir os limites da região de rejeição e aceitação.
5) Calcular a estatística da distribuição escolhida a partir dos valores amostrais obtidos
6) Tomar a decisão (se o p-value for maior que o nível de significância, aceita-se a hipótese nula. Caso contrário, rejeita-se).
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
B)
A partir das informações do enunciado e do banco de dados disponibilizado, formula-se a seguinte hipótese nula:
Ho : A ocorrência de asfixia neonatal não está associada à presença de risco gestacional, o que equivale dizer que a proporção de neonatos que sofreram asfixia com risco gestacional é IGUAL à proporção de neonatos que sofreram asfixia sem risco gestacional .
Assim, a hipótese alternativa também é elaborada:
Ha : Há associação entre a asfixia neonatal e o risco gestacional, o que equivale a dizer que as proporções de neonatos que sofreram asfixia não são iguais entre as populações com e sem risco gestacional.
A partir da formulação dessas hipóteses, escolhe-se o teste a ser utilizado. Como trata-se de variáveis categóricas, escolhe-se, preferencialmente um teste de independência ou do tipo qui-quadrado. Como as variáveis cada elemento da amostra só foi avaliado uma ves no estudo, não há nenhum valor zero em quaisquer destas caselas e em tres das quatro caselas o valor da frequência esperada é maior do que 5, o “Teste do Qui-Quadrado de Pearson” foi escolhido.
Assim, prossegue-se com a escolha do nível de significância (α) do teste. A escolha para esse teste foi de 5%.
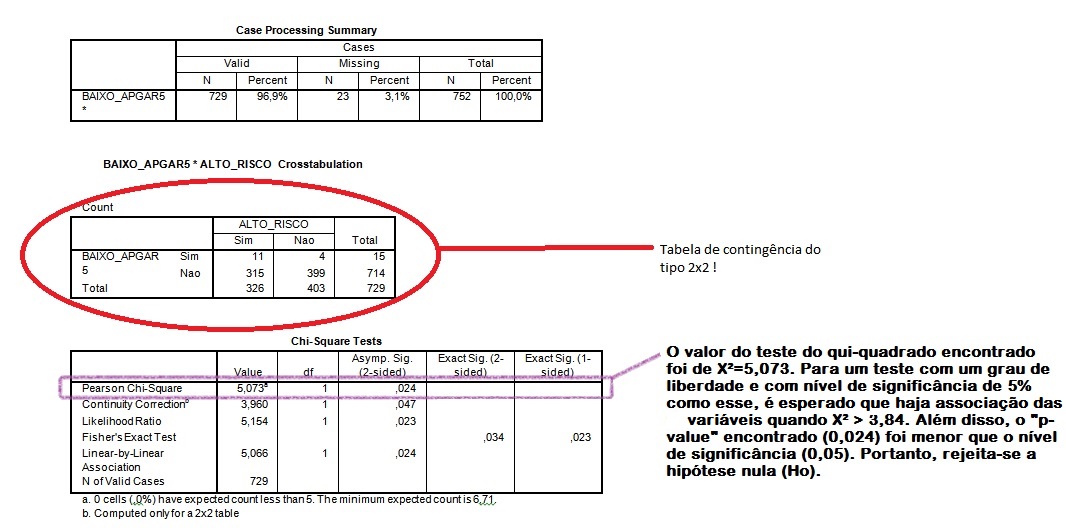
Sabe-se que, nas medidas de associação entre variáveis categóricas com utilização do teste do qui-quadrado, é comum o USO DE TABELAS DE CONTINGÊNCIA. No caso ilustrado, há dois preditores e dois desfechos. Portanto, utiliza-se a tabela de contingência 2x2. Essa é gerada pelo software SPSS no momento do cálculo do qui-quadrado e do valor do p (p-value).
Ao abrir o programa estatístico, clique na aba “Analyze” >> “Descriptive statistics”>> “Crosstabs”. No campo “Row”, coloque a informação “BAIXO_APGAR5” e , no campo “Column”, preencha com a informação “ALTO_RISCO”. No botão “Statistics”, marque a opção “Chi-square”. Observe os resultados:

{kind=link}
{kind=link}
RESPOSTA : O valor do teste do qui-quadrado encontrado foi de X2 = 5,073. Para um teste com um grau de liberdade e com nível de significância de 5% como esse, é esperado que haja associação das variáveis quando X2>3,84. O valor encontrado do qui-quadrado também mostra que há uma grande diferença entre os dados observados e aqueles esperados, reforçando a significância estatística do teste. Além disso, o “p-value” encontrado (0,024) foi menor que o nível de significância utilizado (0,05). Portanto, rejeita-se a hipótese nula e afirma-se que há confiança de 95% para afirmar que existe associação entre a asfixia neonatal e o risco gestacional (hipótese alternativa).
---------------------------------------SÍNTESE DO CONTEÚDO ABORDADO ANTERIORMENTE------------------------------------------
A utilização do teste do qui-quadrado visa verificar se as distribuições de duas ou mais amostras não relacionadas diferem significativamente em relação à determinada variável. Dessa forma, pode-se avaliar a presença de associação entre duas variáveis CATEGÓRICAS (nominais ou ordinais).
O teste do qui-quadrado exige condições para a sua realização:
# É exclusivo para variáveis categóricas;
# Tem preferência por amostras grandes >30;
# Devem ser observações independentes;
# Não se aplica se 20% das observações forem inferiores a 5;
# Não pode haver freqüências inferiores a 1
Passos do teste do Qui-Quadrado :
1)Determinar H0 (As variáveis são independentes ou as variáveis não estão associadas);
2)Estabelecer o nível de significância (α);
3)Determinar o valor dos graus de liberdade (φ), sendo φ = (L – 1) (C – 1), onde L = números de linhas da tabela e C = ao número de colunas (esse dado é gerado na tabela do programa SPSS com a denominação de “df”);
4)Encontrar, portanto, o valor do Qui-quadrado tabelado (o programa SPSS já gera o resultado do qui-quadrado e ainda dá o p-value).
Para encontrar o valor esperado (E) de cada um dos quatro dados da tabela de contigência 2x2, utiliza-se a fórmula a seguir:
E = [(Σ DA LINHA n) X (Σ DA COLUNA n)] ÷ (TOTAL DAS OBSERVAÇÕES)
sendo n = 1, 2 (no caso de tabela 2x2) e "Σ" denota o somatório.
Quando não se tem a ferramenta do SPSS, calcula-se o Qui Quadrado através da fórmula:
X2= Σ [( O - E) ÷ E]2
Se o valor do qui-quadrado for maior que o esperado de acordo com o grau de liberdade do estudo (no exemplo do exercício, X2=5,073>3,84 para gL=1), há associação entre as variáveis. Se o p-value do teste for menor que o nível de significância, refuta-se a hipótese nula. Caso contrário, aceita-se a mesma.
REFERÊNCIAS
--> PAGANO M, GAUVREAU K. Princípios de bioestatística. Tradução da 2ª ed. norte-americana. São Paulo: Pioneira Thomson Learning, 2004.
--> SIQUEIRA, Arminda Lucia; Tibúrcio, Jacqueline Domingues. Estatística na área da saúde: conceitos, metodologia, aplicações e prática computacional. Belo Horizonte: Coopmed, 2011. 520 p.
Indexadores do tema deste exercício
editarComparação entre grupos amostrais em saúde
Bibliografia utilizada
editarREFERÊNCIAS
--> PAGANO M, GAUVREAU K. Princípios de bioestatística. Tradução da 2ª ed. norte-americana. São Paulo: Pioneira Thomson Learning, 2004.
--> SIQUEIRA, Arminda Lucia; Tibúrcio, Jacqueline Domingues. Estatística na área da saúde: conceitos, metodologia, aplicações e prática computacional. Belo Horizonte: Coopmed, 2011. 520 p.